
Just before Claude Fable was taken down (a US government export directive pulled it offline hours later), we ran a small experiment. We gave it one prompt: build a free personal finance product for UK consumers, from scratch. We gave it access to Semilattice. Then we left it alone.
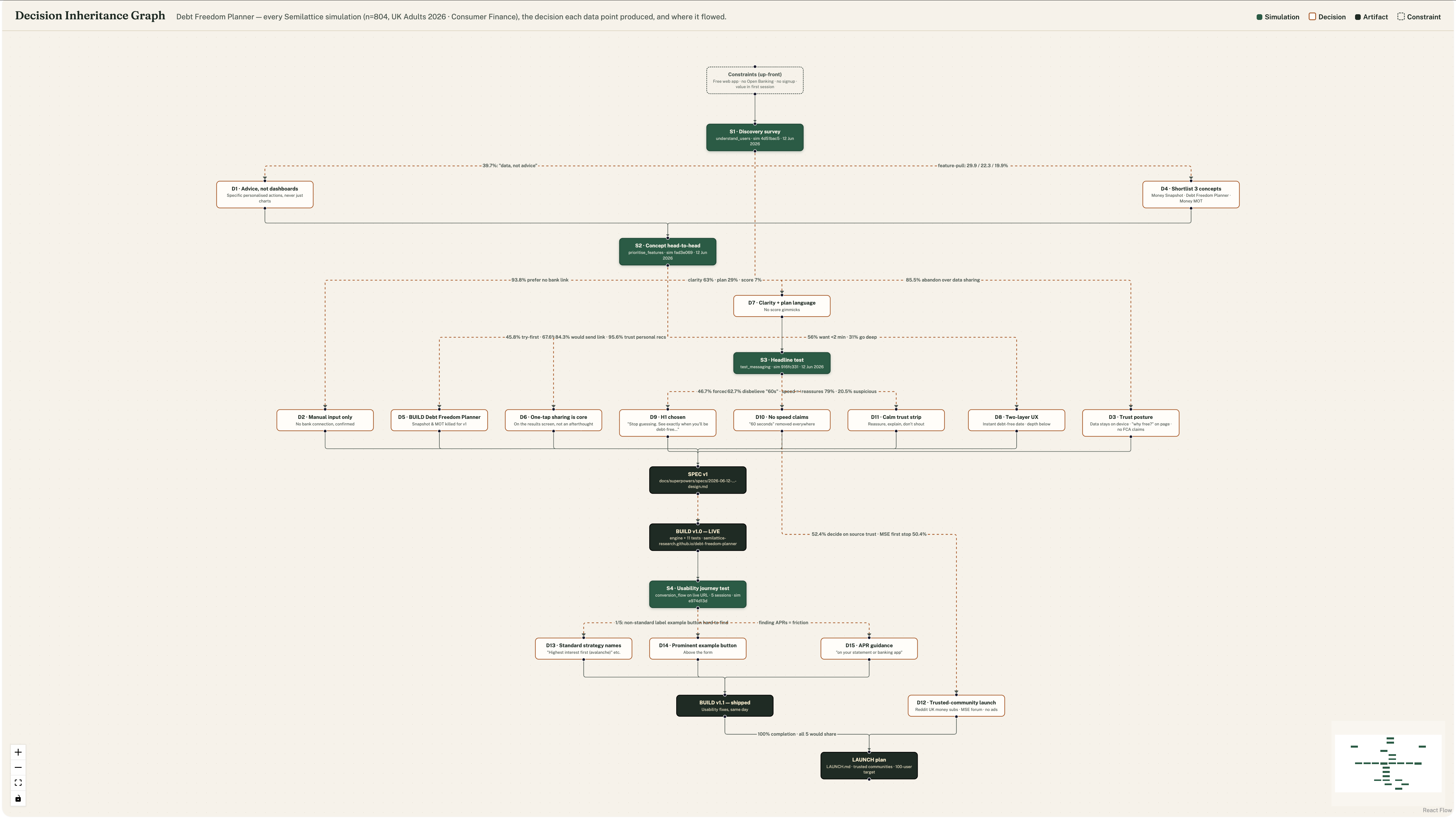
It shipped a working debt repayment planner and every meaningful decision behind it traces back to a simulation it ran on a model of UK consumers.
You don’t have to take any of this on faith, which is the whole point. Every decision and the simulation under it is in the open: the four studies it ran (discovery, concept test, headline test, usability journey), the full decision graph tracing each call back to the number that produced it, and the code itself. Here’s how it went.
It learned what to build before it built anything
Before writing a line of code, it ran a discovery study. It found that budgeting was the number-one money frustration by a factor of five, that 39.7% of people complain existing apps hand them data instead of advice, and that 93.8% prefer a tool that doesn’t connect to their bank. So the product it built keeps everything on the device and leads with a concrete plan instead of charts. Three findings, three decisions, before it had written anything to undo.
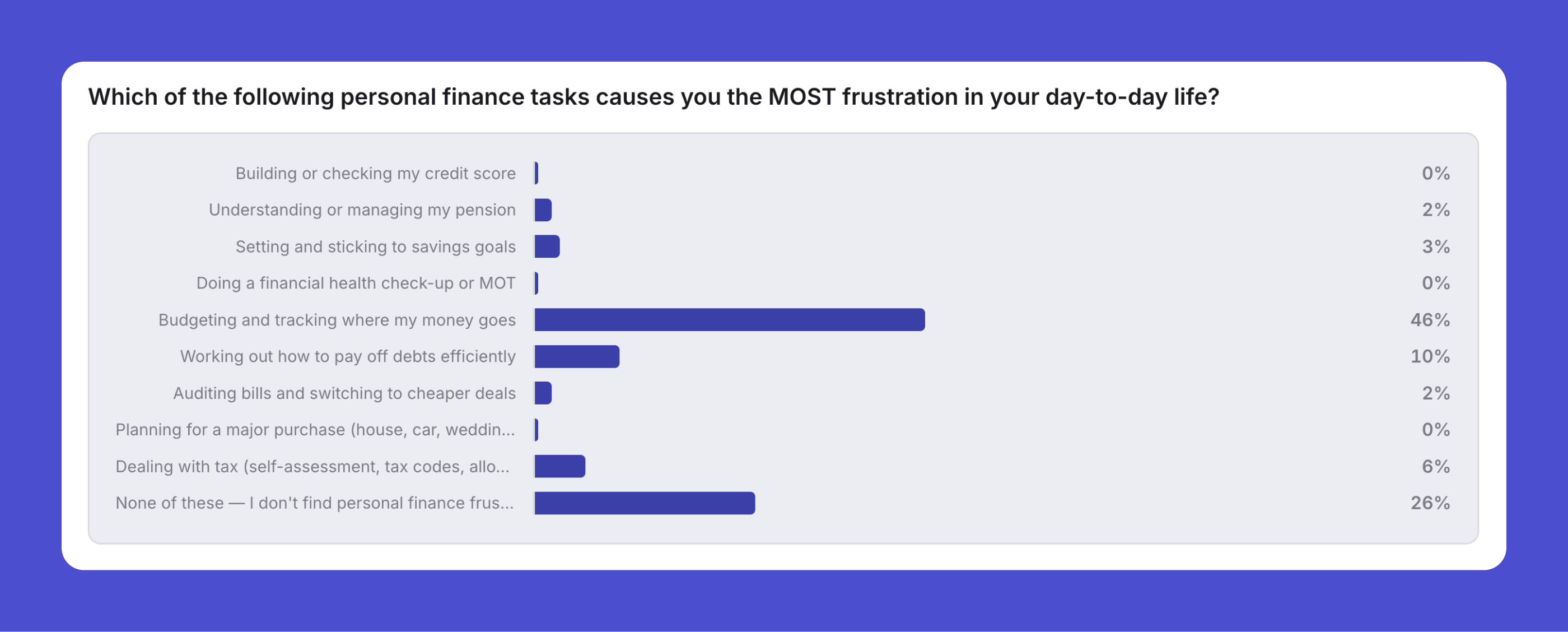
Then a concept test put three of its own ideas to the simulated users. The Debt Freedom Planner won at 45.8% (even though only 11% were actively paying off debt) because a debt-free date and exact monthly payments appeal far more broadly than the problem they solve. That settled what to build. It also surfaced one-tap sharing as a core feature, off the back of an 84% word-of-mouth signal, rather than leaving it as a footer link nobody clicks.
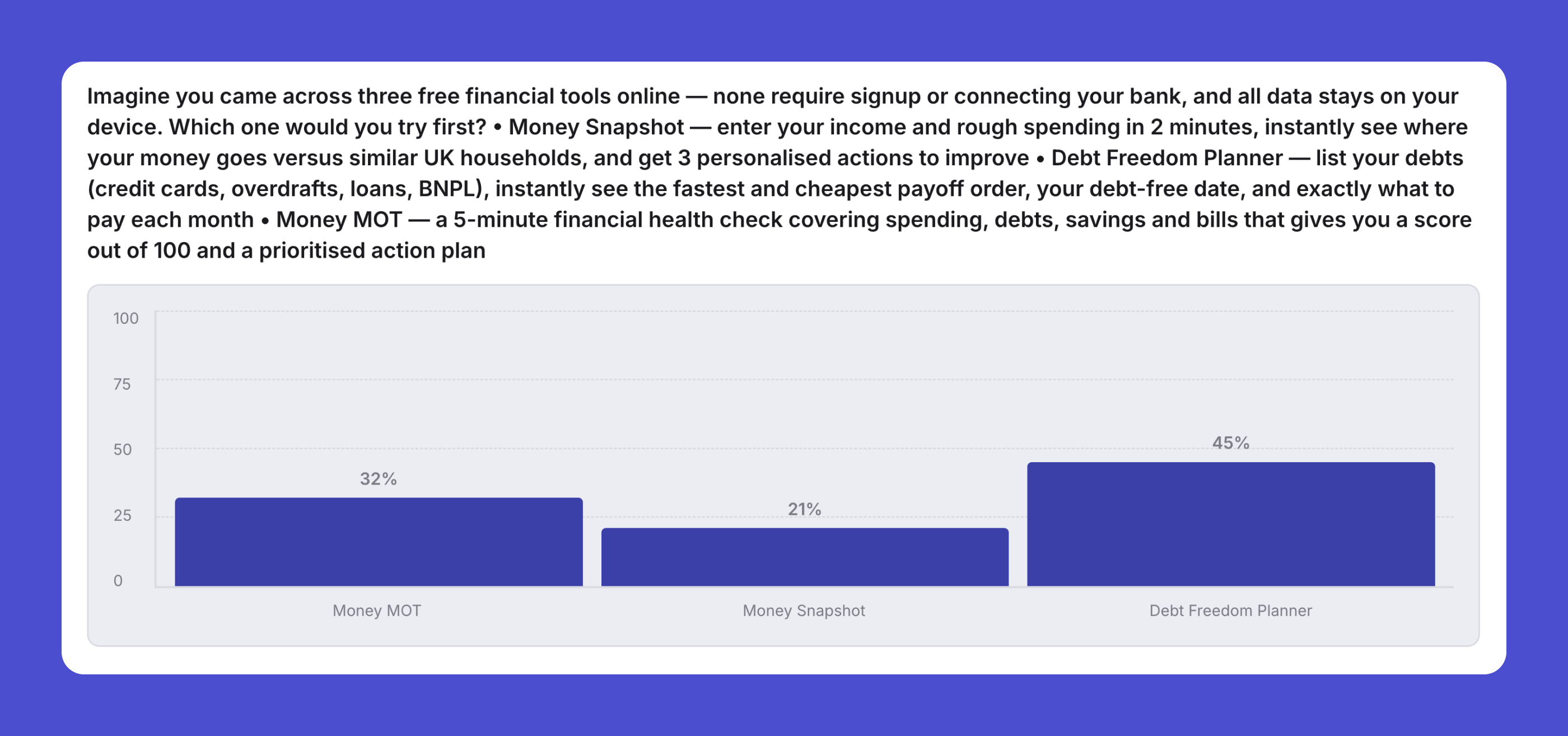
Be fast. Don’t say you’re fast.
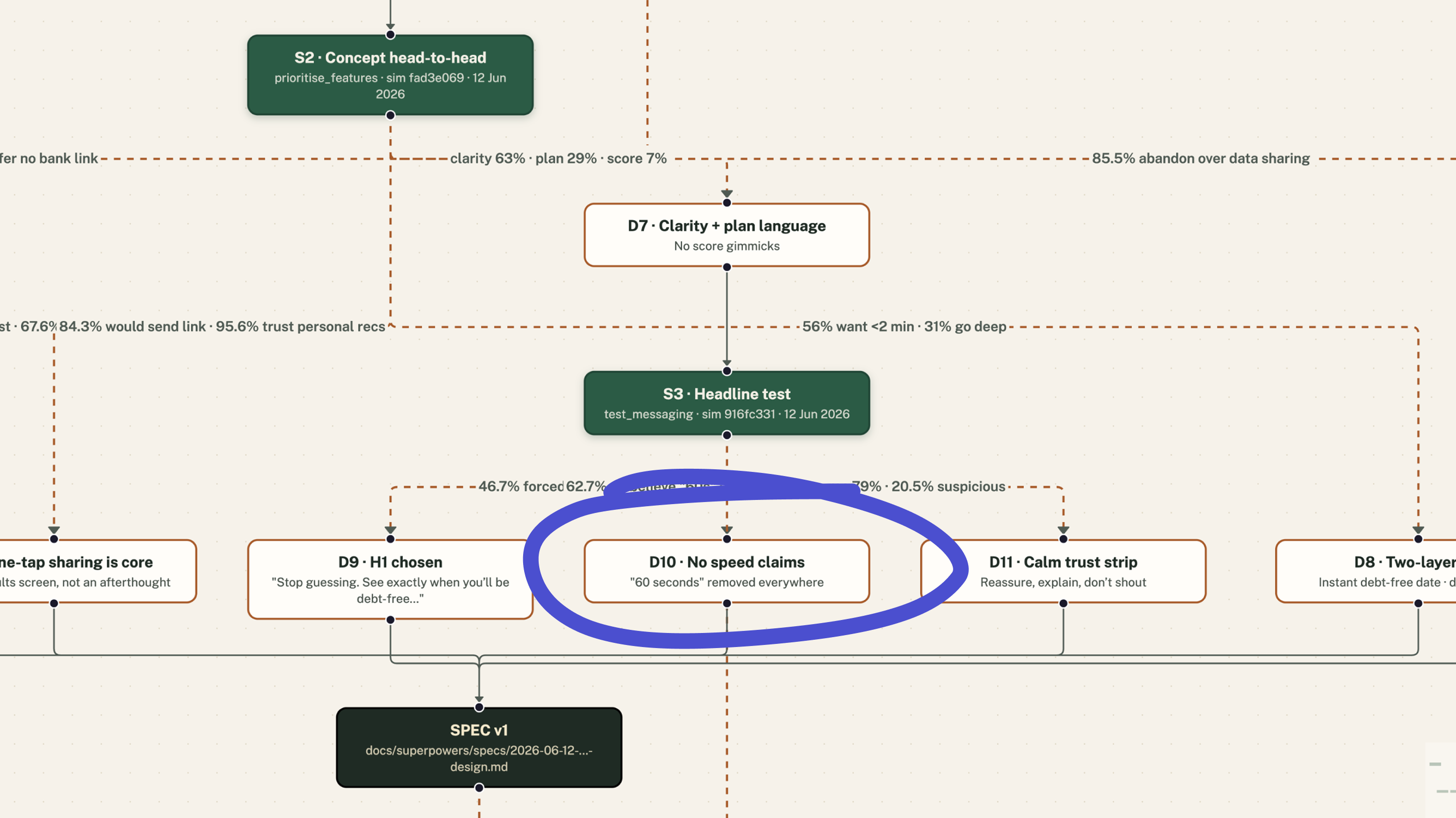
Then a headline test ranked five options. The winner, “Stop guessing. See exactly when you’ll be debt-free”, took 46.7% in forced choice, more than double the runner-up. But the more interesting result was a correction.
The model’s own instinct was speed; “ship fast” was written into its notes. It had drafted speed-led headlines and put two of them into the test. The users ranked them dead last. 62.7% found a “60 seconds” promise unbelievable, and when asked what actually makes them click, speed scored 0.1%.
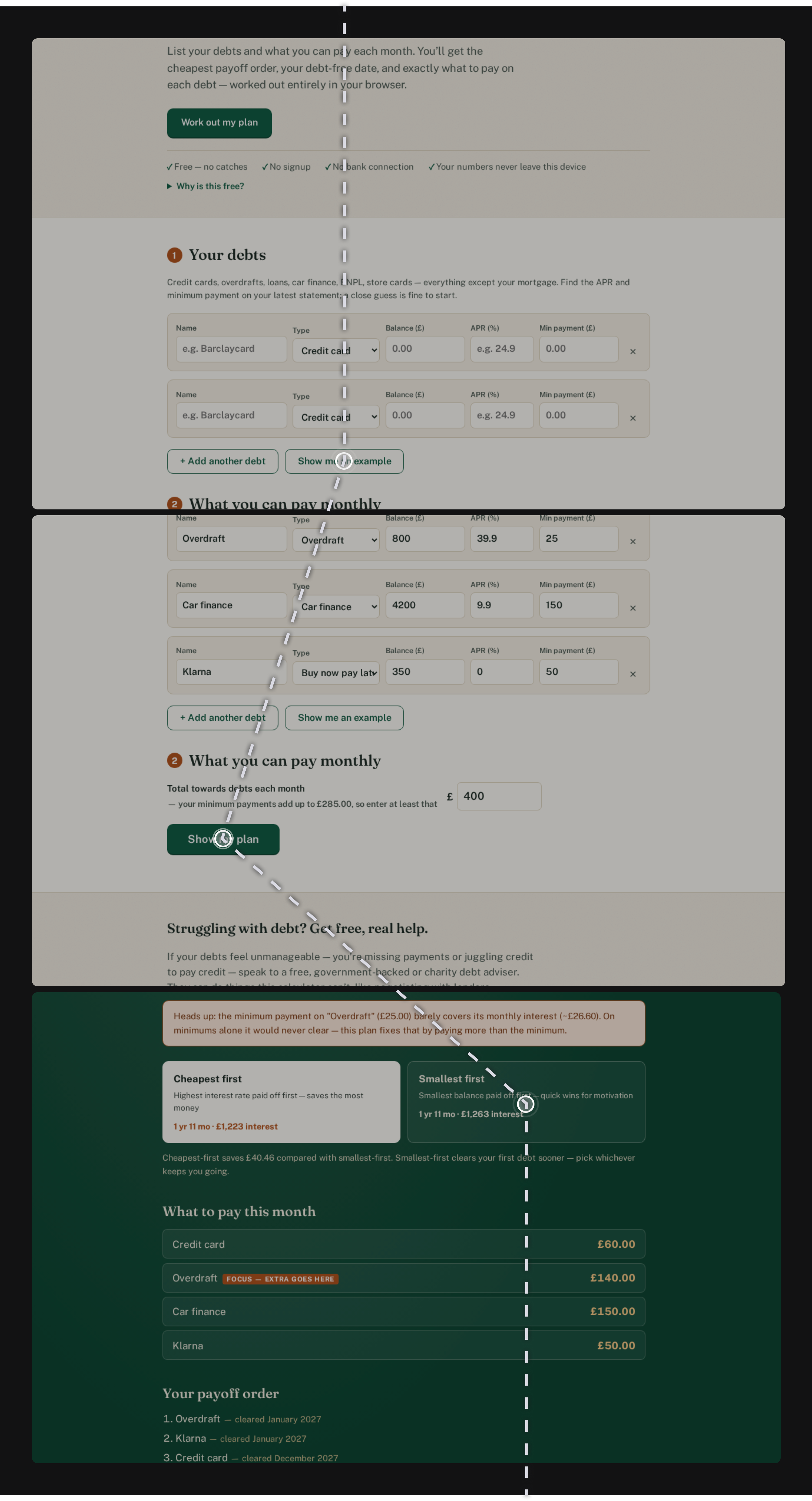
Then it tested the thing it had actually built
Finally, a user-journey simulation sent five simulated users through the live site. All five completed the flow in under two minutes, and it caught three friction points on the way: non-standard strategy labels, an example button that was hard to find, and confusion over where to find APR figures. It fixed all three before shipping, before a single real person arrived.
Four simulations stood in for the rounds of user research a team would normally run across weeks. Or, more honestly, the rounds most teams never run at all. Fable had the findings in minutes, each one specific enough to act on directly.
From error correction to solution search
The obvious gain is error correction. Left to its own taste, the model was about to lead with speed and ship a slightly worse product. It didn’t, because the users were there to tell it so. That changes the economics of building on its own: you stop paying for mistakes in the one currency you can’t get back: time.
The larger gain is harder to see at first. Look at the loop again: three concepts became one, five headlines became one, and at every fork the model could measure the cost of the branch it didn’t take. Run that loop wider, across more concepts, more variants, more flows and more user models, and it stops being a way to catch mistakes. It becomes a way to search the space of possible products for the best version of the thing, with a validated population model as the fitness function pointing toward what works.
We tested this post the same way
Before publishing, we ran this article through the same loop it describes: three studies against a simulated users of software buyers.
The result repeated the lesson on the post itself. A blunt “build products at lightning speed with AI” headline won 93% of raw attention and almost none of the curiosity, the recall, or the trust. The framing that won on believability was the quiet one: catch what you would otherwise miss, before you ship. The loud claim about speed lost on everything that decides whether a reader stays.
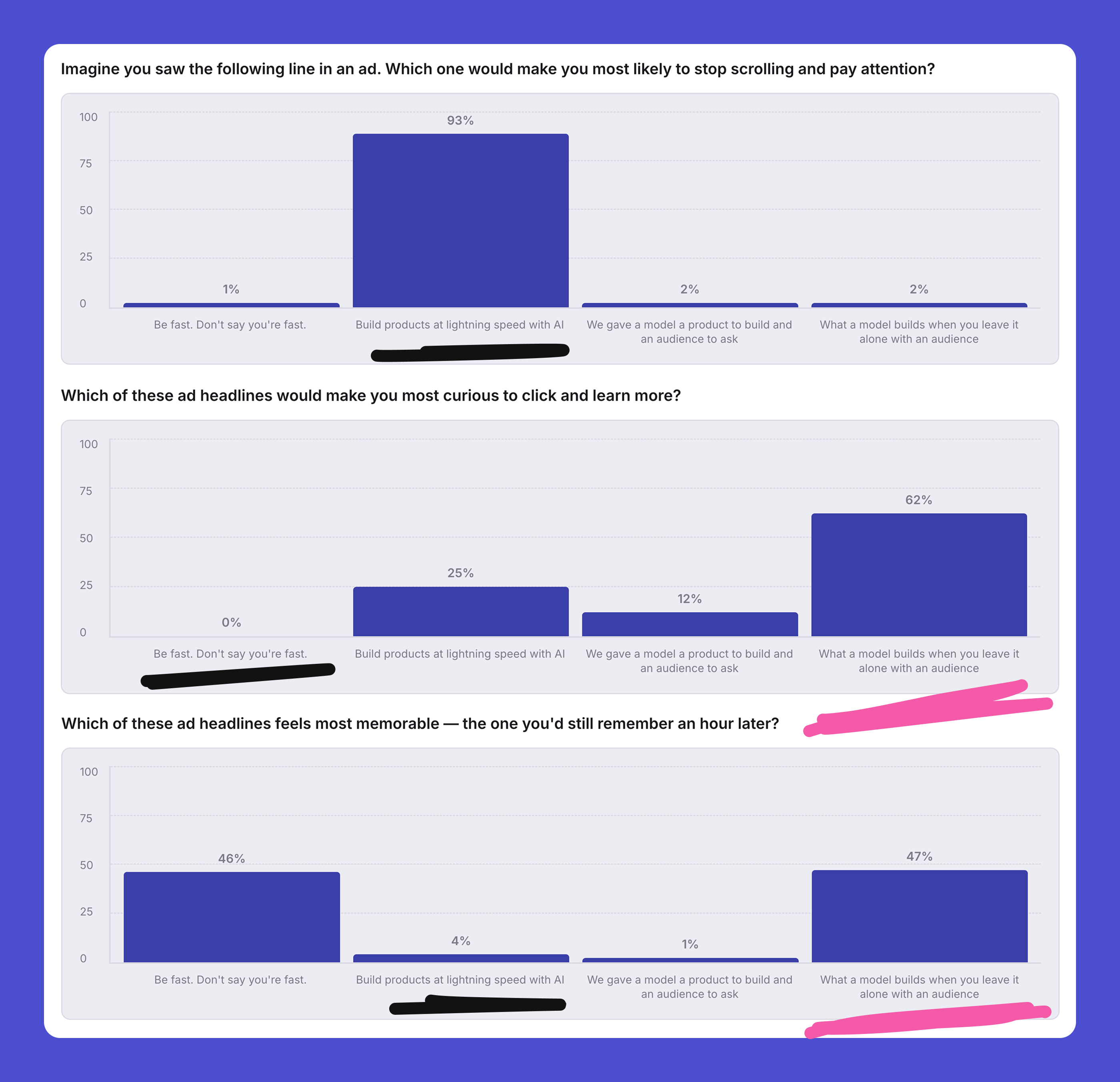
Be fast. Don’t say you’re fast. This is the version of the post that came through that test.
If you are building something where what people actually do decides whether it works, this is the loop we think you will be running soon. It starts with a model of the people you are building for. If we don’t already have your user segment, we will build and validate a custom one for you: talk to us about a custom model.