
Semilattice is a user behaviour API designed for rapid decision-making and programmatic personalisation. Accuracy is at its core and prediction outputs always come with accuracy estimates. Today we’re excited to announce test batches: a new evaluation feature which lets you test population models against specific use cases.
Let’s explore how this works with a nationally representative model of UK adults.
Automatic cross-validation
Before we talk about test batches, it’s important to understand Semilattice’s default testing method: leave one out cross-validation (or 1-fold cross-validation). This uses a population model’s seed data to evaluate its accuracy.
The seed data used to create our UK NatRep 2025 model contains 53 questions. Cross-validation temporarily removes each of those questions (and their answer data) from the population model, uses the remaining 52 questions to predict that question, and then compares the prediction with the ground truth to calculate an accuracy score. This is repeated for all questions. The scores are then averaged to calculate the population model’s overall accuracy. The idea is that any one of the seed data questions could be a new question you might want to predict.
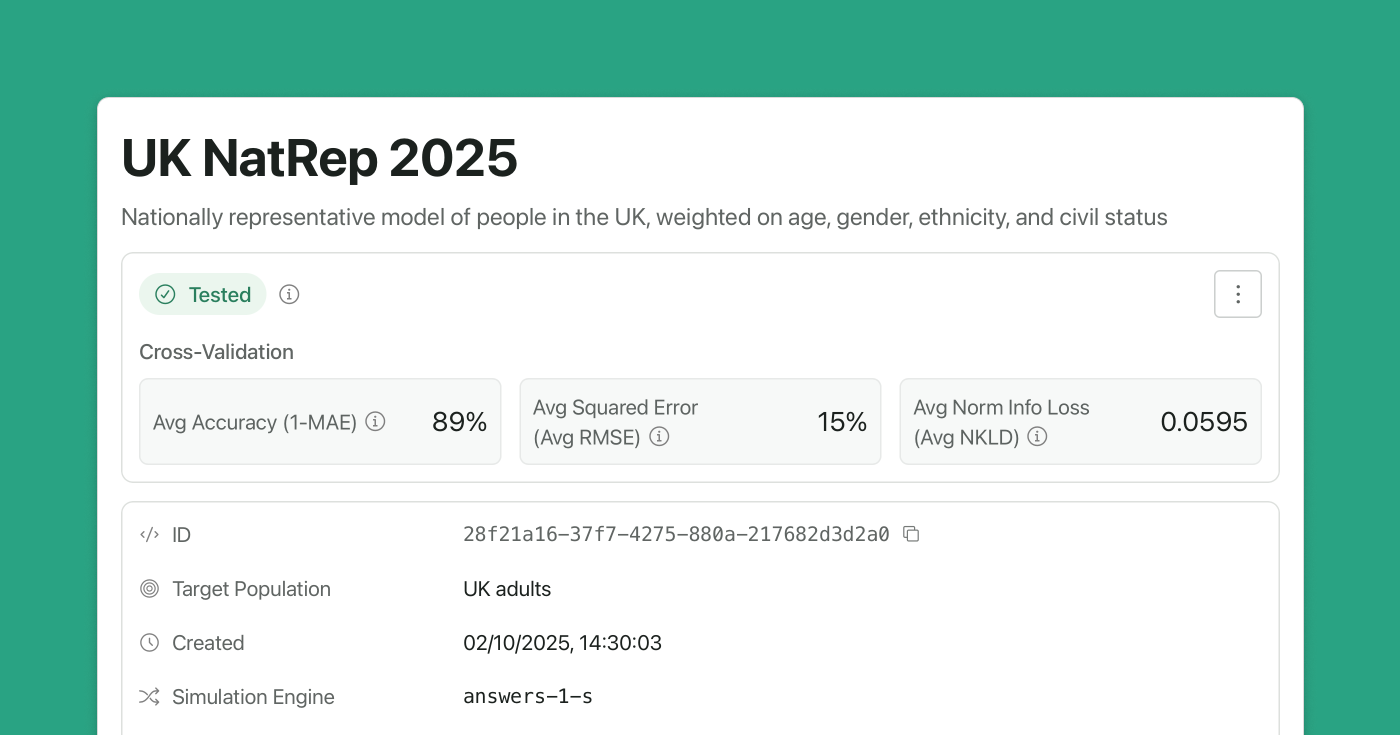
Running this test on our UK NatRep 2025 model gives us an overall average accuracy of 89%. We also calculate average squared error and average normalised information loss.
While this type of cross-validation is informative, its limitation is that it only tells you about the model’s accuracy at predicting questions which are similar to the questions in the seed data. How do we know whether a population model does a good job at predicting other questions?
Test batches
Test batches are designed for exactly this purpose. They let you test a population model against a completely different set of questions than those in the seed data.
Imagine we want to evaluate our UK population model’s accuracy at predicting preferences and attitudes around finance.
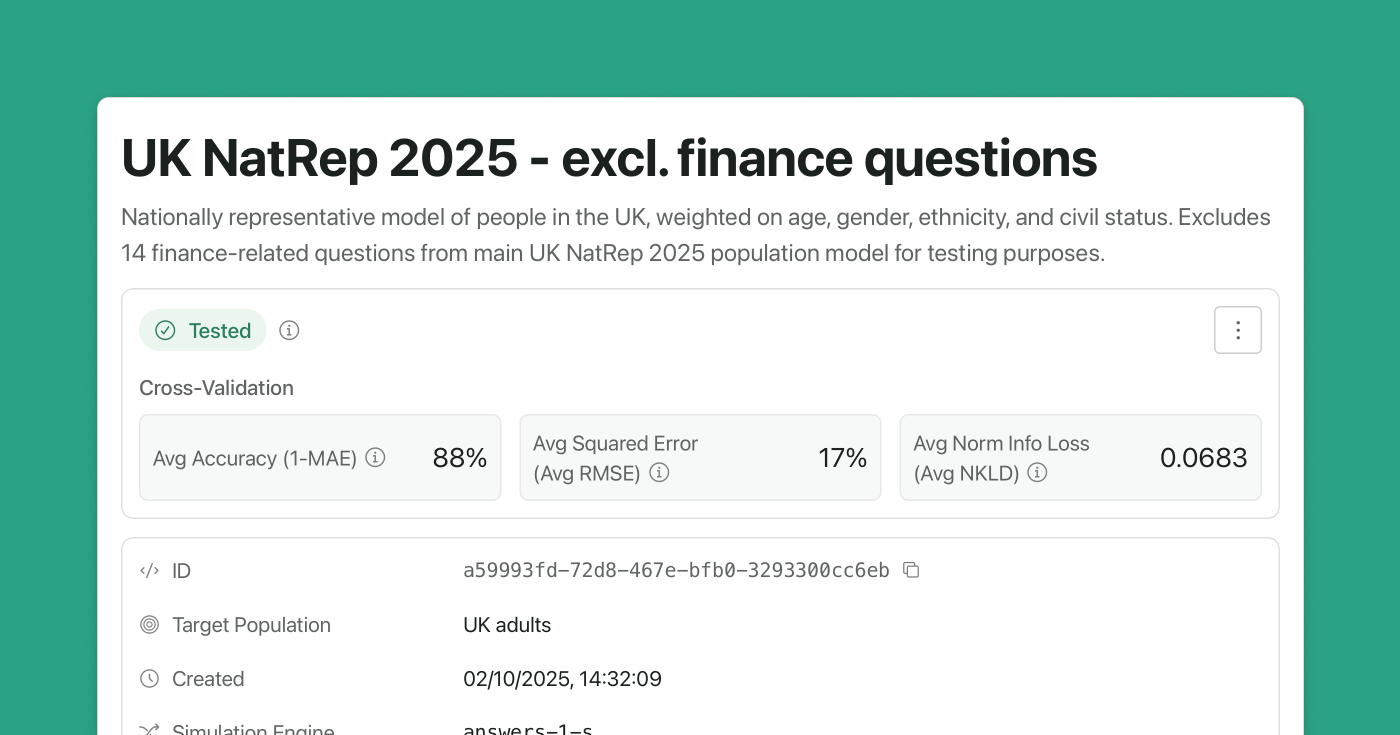
The model’s seed data contained 53 questions. These questions covered demographics, preferences around AI, personality traits, and finance. We will separate out the 14 finance-related questions and create a new UK NatRep population model with the remaining 39 questions. We’ll then test that model’s accuracy by running a test batch with those 14 finance questions. The idea is that the 14 finance questions represent a specific prediction task you want to test the model against. The 39 questions in the model’s seed data aren’t focused on finance, so the evaluation question we are asking is whether demographic, AI preference, and personality trait questions predict finance questions.
First though, let’s run leave one out cross-validation on this new UK NatRep model to see the effect of removing those 14 finance questions. The accuracy drops slightly to 88%; still pretty good.
Now, let’s see if this smaller population model can predict the finance questions. To do that, we’ll call the API’s tests.create method passing in the ground truth answer distributions to those finance questions and providing details of this test batch via the batch parameter:
semilattice.tests.create(
population_id="a59993fd-72d8-467e-bfb0-3293300cc6eb",
batch={
"name": "Finance-related questions",
"description": "A test batch of 14 finance-related questions",
"effective_date": "2025-09-15"
},
tests=tests # list of questions, answer options, ground truth
)
Test predictions take ~15-20 seconds to run and the API will run up to 4 at a time. You can view the test batch results on the population model page under the Model > Tests tab, or fetch the results from the API via tests.get_batch.
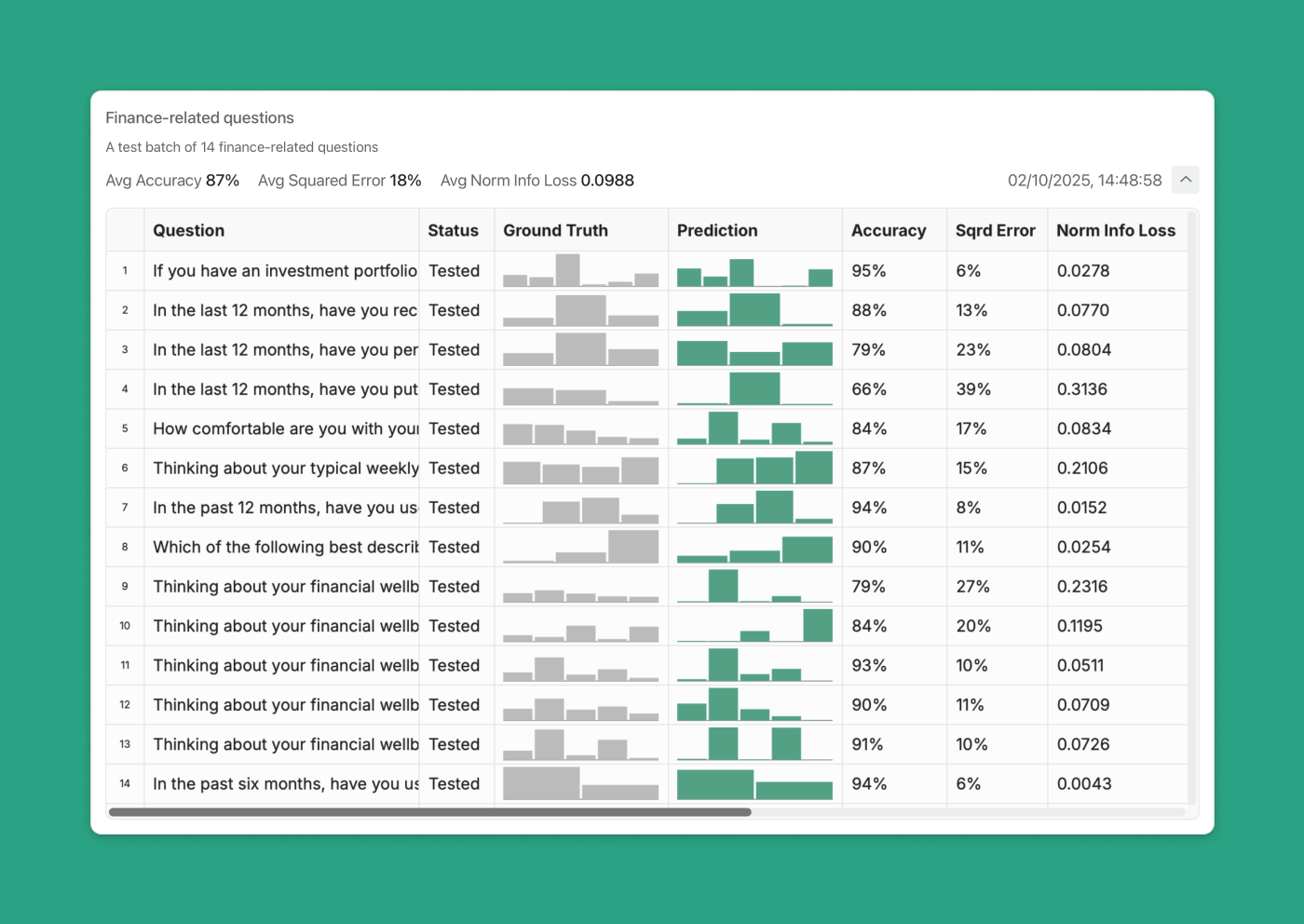
The results are in: 87% accuracy. A little less than the overall model’s accuracy as tested via cross-validation when all 53 questions are included, but still pretty good. You can view all the individual test predictions within the batch to explore question-level accuracy.
Here, for example, is an 90% accurate test prediction:
Which of the following best describes how you primarily do your day-to-day banking?
Accuracy: 90.1%
This was just a test to demonstrate test batches and explore whether demographics, AI preferences, and personality traits can predict preferences around finance. In practice, if you wanted to predict finance-related questions you would include all the finance-related data you have in the population model's seed data to maximise accuracy.
You can read more about our evaluation features and test batches in the docs.
Get started with the API for free
Semilattice is free to try. Sign up to get an API key and run your first prediction in seconds. We are also excited to chat to teams who are thinking about building user simulation into their products or data science workflows. Book some time to chat to us here.